Falvey Library Service Alert: EZBorrow Unavailable on Monday, Dec. 5


Staying in Scandinavia for this week’s word of the week (if you haven’t read last week’s Peek at the Week, give it a look) we’re learning about the relaxing Swedish coffee break, “fika.” Although fika is a daily part of people’s lives in Sweden, we could use a little more of it in America.
Fika is more than just a coffee break. It’s an opportunity to slow down, grab coffee, pick up a sweet treat, and engage in meaningful conversation with friends. I know I’m not very good at the “slowing down” part of a coffee break, but by focusing on engaging in fika throughout my day, I can work to be more mindful and accomplish more the rest of the day.
Want to learn more about the art of fika? Check out The Little Book of Fika: The Uplifting Daily Ritual of the Swedish Coffee Break by Linda Balslev in Falvey’s collection.
Monday, Nov. 15th–Friday, Jan. 7th
Cabinets of Curiosity Exhibit / Falvey First Floor / Free & Open to the Public
Monday, Nov. 15th–Friday, Nov. 19th
Undergraduate Research Symposium Poster Display / 8 a.m.–5 p.m. / Falvey’s Digital Scholarship Lab & Room 205 / Free & Open to the Public
Hunger and Homelessness Awareness Week Display / First Floor Display Case
Monday, Nov. 15th–Wednesday, Nov. 17th
Virtual VuFind® Summit 2021 / 9 a.m.–12 p.m. each day / Virtual / Register Here
Monday, Nov. 15th
Mindfulness Mondays / 1–1:30 p.m. / Virtual / https://villanova.zoom.us/j/98337578849
Wednesday, Nov. 17th
Fall 2021 Falvey Forum Workshop Series: Creating Interactive GIS Maps with Leaflet and R / 12–1:30 p.m. / Virtual / Register Here
GIS Day Lecture: Signe Peterson Fourmy, JD, PhD, Villanova University, on “Digital Mapping & Last Seen Ads” / 5:30–6:30 p.m. / Virtual / Register Here
Thursday, Nov. 18th
GTU Honor Society Talk & GEV Colloquium Lecture: Gordon Coonfield, PhD, on “How Neighborhoods Remember: Mapping Memory and Making Place in Philadelphia” / 5:30–6:30 p.m. / Mendel 154 & Virtual / Register Here
Friday, Nov. 19th
Villanova Gaming Society Meeting / 2:30–4:30 p.m. / Speakers’ Corner / Free & Open to the Public
November 19, 1863 – President Lincoln delivers Gettysburg Address
On November 19, 1863, President Lincoln delivered arguably one of the best speeches in the country’s history at the dedication of the Soliders’ National Cemetery in Gettysburg, Pennsylvania. The 2-3 minute speech consisting of less than 275 words ended up being exceptionally more powerful than the 2-hour speech delivered by orator Edward Everett.
Here are the concluding remarks from his little speech: “The world will little note, nor long remember what we say here, but it can never forget what they did here. It is for us the living, rather, to be dedicated here to the unfinished work which they who fought here have thus far so nobly advanced. It is rather for us to be here dedicated to the great task remaining before us—that from these honored dead we take increased devotion to that cause for which they gave the last full measure of devotion—that we here highly resolve that these dead shall not have died in vain—that this nation, under God, shall have a new birth of freedom—and that government of the people, by the people, for the people, shall not perish from the earth.”
A&E Television Networks. (2010, March 10). President Lincoln delivers Gettysburg Address. History.com. Retrieved November 10, 2021, from https://www.history.com/this-day-in-history/lincoln-delivers-gettysburg-address.
 Jenna Renaud is a graduate student in the Communication Department and graduate assistant in Falvey Memorial Library.
Jenna Renaud is a graduate student in the Communication Department and graduate assistant in Falvey Memorial Library.

Imagine searching the library catalog for books such as Migrant Deaths in the Arizona Desert and Whose Child am I?: Unaccompanied, Undocumented Children in U.S. Immigration Custody—and seeing the term “illegal aliens” appear on the results screen. Library users everywhere have encountered that term for many years, as it has long been the official Library of Congress subject heading assigned to books and other materials on the topic of immigrants who are undocumented.
Users of Falvey Memorial Library’s catalog no longer encounter this pejorative subject heading in the public display, due to changes made by Falvey staff this past fall. Instead of the term “illegal aliens,” the Falvey catalog now displays “undocumented immigrants” as a subject heading term.
The changes affect variations on the subject heading as well; for example, “children of undocumented immigrants” now appears instead of “children of illegal aliens.” All instances when “alien” referred to a human being have been changed.
Falvey staff members recognize that terms like “illegal alien” are not in alignment with Falvey’s or Villanova’s support of diversity as an integral component of our shared mission and values. This change to the library catalog is a reflection of Villanova as a welcoming community. We hope that it is also a step toward a respectful, globally-minded society.
Falvey Memorial Library, like most academic and public libraries, uses Library of Congress subject headings to organize materials and make them discoverable to users. This cooperative system allows libraries to share resources. Subject headings are set by the Library of Congress, and, in general, changes to subject headings go through a process of approval there.
Librarians and college students lobbied several years ago to have the “illegal aliens” subject heading replaced with other terms in all library catalogs, and the change was approved by the Library of Congress in 2016. This decision was widely supported by the library community. The 114th Congress intervened and overturned the decision before it could be implemented.
The timing was inspired in part by the 2019 documentary Change the Subject. This film shares the story of a group of student activists at Dartmouth College who began the movement for change. The Villanova community had the opportunity to view the film at a screening this fall, organized by Deborah Bishov, Social Sciences & Instructional Design Librarian, and Raúl Diego Rivera Hernández, PhD, Assistant Professor in the Department of Romance Languages and Literatures. The event featured a discussion with two of the filmmakers behind Change the Subject, Jill Baron and Óscar Rubén Cornejo Cásares.
During conversations leading up to the screening, Falvey librarians—with the approval of Millicent Gaskell, University Librarian, and Jee Davis, Associate University Librarian for Collections & Stewardship—made the decision to change the subject in Falvey’s catalog.
“Libraries use the subject headings established by the Library of Congress. The process for requesting a subject heading change was followed and the Library of Congress approved. In an unprecedented move, Congress overrode that decision. It’s been almost four years since the Library of Congress gave its approval. We believe now is the time for individual libraries to take the lead,” Davis says.
Since the Library of Congress is still using “illegal aliens” in its shared catalogue, Falvey staff created code to display “undocumented immigrants” instead. Demian Katz, Director of Library Technology, worked with librarians at Falvey to alter the subject headings in VuFind, an open-source software for displaying the information in library catalogs. It was developed at Villanova University and is used by libraries around the world.
One of the advantages of using open source software at Falvey is that staff can make customizations more easily than if they had to negotiate with a vendor to achieve the same results. Katz says, “In this instance, it only took a few hours of work spread across a few days to fully solve the technical problems involved.” While only the new subject headings appear in our public catalog, the old subject headings are still searchable.
Libraries using VuFind can implement the same solution using the documentation on the Library’s technology blog. The Villanova University Charles Widger School of Law has already implemented this update into their catalog.
“This change is about upholding our professional values to connect people to information and recognizing the power of the language we use as we do that,” Bishov says. “Making this change means that people who use our public catalog will not encounter this dehumanizing term in subject headings in the course of doing their research. And we’ll also be using terminology that matches language widely accepted by the people to whom it refers, by journalists, and by scholars.”


Deborah Bishov is Social Sciences & Instructional Design Librarian and Shawn Proctor is Communication & Marketing Program Manager at Falvey Memorial Library.
Background
Recent discussions related to the documentary, Changing the Subject, raised an interesting technical question: what should you do if your local needs come into conflict with national practices for describing a particular subject?
While Changing the Subject specifically addresses the conflict between using the terms “Illegal aliens” vs. “Undocumented immigrants,” we took this conversation as an opportunity to reduce user confusion over a whole host of terms using the word “Alien” to mean something other than “Extraterrestrial.”
The challenge, of course, is that this is not a problem that can be easily solved by editing records in our Integrated Library System. Not only are the tools for changing headings fairly difficult to use, but there is also the problem that new records will be constantly getting loaded into the system as we acquire new items, making maintenance an ongoing headache.
Enter VuFind: since we have an open source discovery layer to allow users to search our collection, and all of the records in our Integrated Library System are automatically loaded into VuFind through a software process, this gives us an opportunity to introduce some data transformations. By solving the problem once, we can introduce a system that will automatically keep the problem solved over time, without any ongoing record-editing maintenance.
Solution: Part 1 – Indexing Rules
The first part of the solution is to introduce some mapping into our MARC record indexing rules. We ended up adding these lines to our marc_local.properties file in VuFind’s local import directory:
topic_facet = 600x:610x:611x:630x:648x:650a:650x:651x:655x, (pattern_map.aliens) topic = custom, getAllSubfields(600:610:611:630:650:653:656, " "), (pattern_map.aliens2) pattern_map.aliens.pattern_0 = ^Alien criminal(.*)=>Noncitizen criminal$1 pattern_map.aliens.pattern_1 = ^Alien detention centers(.*)=>Detention centers$1 pattern_map.aliens.pattern_2 = ^Alien labor(.*)=>Noncitizen labor$1 pattern_map.aliens.pattern_3 = ^Alien property(.*)=>Foreign-owned property$1 pattern_map.aliens.pattern_4 = ^Aliens(.*)=>Noncitizens$1 pattern_map.aliens.pattern_5 = ^Children of alien laborers(.*)=>Children of noncitizen laborers$1 pattern_map.aliens.pattern_6 = ^Illegal alien children(.*)=>Undocumented immigrant children$1 pattern_map.aliens.pattern_7 = ^Illegal aliens(.*)=>Undocumented immigrants$1 pattern_map.aliens.pattern_8 = ^Children of illegal aliens(.*)=>Children of undocumented immigrants$1 pattern_map.aliens.pattern_9 = ^Women illegal aliens(.*)=>Women undocumented immigrants$1 pattern_map.aliens.pattern_10 = keepRaw pattern_map.aliens2.pattern_0 = ^Alien criminal(.*)=>Noncitizen criminal$1 pattern_map.aliens2.pattern_1 = ^Alien detention centers(.*)=>Detention centers$1 pattern_map.aliens2.pattern_2 = ^Alien labor(.*)=>Noncitizen labor$1 pattern_map.aliens2.pattern_3 = ^Alien property(.*)=>Foreign-owned property$1 pattern_map.aliens2.pattern_4 = ^Aliens(.*)=>Noncitizens$1 pattern_map.aliens2.pattern_5 = ^Children of alien laborers(.*)=>Children of noncitizen laborers$1 pattern_map.aliens2.pattern_6 = ^Illegal alien children(.*)=>Undocumented immigrant children$1 pattern_map.aliens2.pattern_7 = ^Illegal aliens(.*)=>Undocumented immigrants$1 pattern_map.aliens2.pattern_8 = ^Children of illegal aliens(.*)=>Children of undocumented immigrants$1 pattern_map.aliens2.pattern_9 = ^Women illegal aliens(.*)=>Women undocumented immigrants$1 pattern_map.aliens2.pattern_10 = (.*)=>$1
This uses two very similar, but subtly different, pattern maps to translate terminology going to the topic_facet and topic fields.
The key difference is in pattern_10 of the two maps — for the “aliens” pattern, we use the “keepRaw” rule. This means that we translate headings when they match one of the preceding patterns, and we keep them in an unmodified form when they don’t. Thus, with this pattern, none of the headings will ever get indexed in their original forms; only in the translated versions. This is because we do not want outdated terminology to display in search facet lists.
On the other hand, in the “aliens2” pattern, we use a regular expression to always index the original terminology IN ADDITION TO any translated terminology. Even though we have opinions about which terms should be displayed, users may still have expectations about the older terminology. By indexing both versions of the terms, we make sure that searches will work correctly no matter how the user formulates their query.
Solution: Part 2 – Custom Code
Unfortunately, index rules alone do not fully solve this problem. This is because when working with MARC records, VuFind displays subject headings extracted directly from the raw MARC data instead of the reformatted values stored in the Solr index. This allows VuFind to take advantage of some of the richer markup found in the MARC, but in this situation, it means that we need to do some extra work to ensure that our records display the way we want them to.
The solution is to create a custom record driver in your local VuFind installation and override the getAllSubjectHeadings() method to do some translation equivalent to the mappings in the import rules. Here is an example of what this might look like:
<?php
namespace MyVuFind\RecordDriver;
class SolrMarc extends \VuFind\RecordDriver\SolrMarc
{
/**
* Translate "alien" headings.
*
* @param string $heading Input string
*
* @return string
*/
protected function dealienize($heading)
{
static $regexes = [
'/^Alien criminal(.*)/' => 'Noncitizen criminal$1',
'/^Alien detention centers(.*)/' => 'Detention centers$1',
'/^Alien labor(.*)/' => 'Noncitizen labor$1',
'/^Alien property(.*)/' => 'Foreign-owned property$1',
'/^Aliens(.*)/' => 'Noncitizens$1',
'/^Children of alien laborers(.*)/' => 'Children of noncitizen laborers$1',
'/^Children of illegal aliens(.*)/' => 'Children of undocumented immigrants$1',
'/^Illegal alien children(.*)/' => 'Undocumented immigrant children$1',
'/^Illegal aliens(.*)/' => 'Undocumented immigrants$1',
'/^Women illegal aliens(.*)/' => 'Women undocumented immigrants$1',
];
foreach ($regexes as $in => $out) {
$heading = preg_replace($in, $out, $heading);
}
return $heading;
}
/**
* Get all subject headings associated with this record. Each heading is
* returned as an array of chunks, increasing from least specific to most
* specific.
*
* @param bool $extended Whether to return a keyed array with the following
* keys:
* - heading: the actual subject heading chunks
* - type: heading type
* - source: source vocabulary
*
* @return array
*/
public function getAllSubjectHeadings($extended = false)
{
// Get extended headings from the parent:
$headings = parent::getAllSubjectHeadings(true);
foreach ($headings as $i => $heading) {
if (isset($headings[$i]['heading'][0])) {
$headings[$i]['heading'][0]
= $this->dealienize($headings[$i]['heading'][0]);
}
}
// Reduce to non-extended format if necessary:
if (!$extended) {
$reduce = function ($var) {
return serialize($var['heading']);
};
return array_map(
'unserialize', array_unique(array_map($reduce, $headings))
);
}
return $headings;
}
}
You can learn more about building custom record drivers in the VuFind wiki.
Conclusions
While it requires a bit of redundancy, solving this problem with VuFind is still a great deal simpler and less painful than trying to maintain the records in a different way. If you would like to adopt a similar solution in your library and need more information beyond the code and configuration shared here, please feel free to reach out to the VuFind community through one of the methods listed on our support page.
Did you know that an innovative search engine used by libraries in numerous countries for browsing catalogs was developed right here at Villanova University? It’s called VuFind, and its open source coding allows for continued innovation by institutions and individuals throughout the world.
Some of the most important contributors are coming to Falvey Memorial Library this week, on Oct. 10 and 11, for VuFind Summit 2016. Registration has closed, but you can still attend the conference virtually on the Remote Participation section of the VuFind Summit webpage. Speaking of remote participation, this year’s VuFind Summit will feature a video conference with another VuFind Summit occurring concurrently in Germany.

The VuFind Summit 2015 group.
This year’s conference includes speakers such as Andrew Nagy, Leila Gonzales and Bob Haschart, among others. Nagy, one of the developers involved in starting the VuFind project here at Villanova, will be giving a talk on his new FOLIO project. FOLIO is another open source project that will integrate VuFind as it attempts to help libraries work together in new ways.
Gonzales has devised a method for using VuFind for geographical data. On her map interface, a user can draw a shape and pull full records from the designated space. Her talk features a brainstorming session for thinking up new features and applications for her software. Haschart will discuss his new SolrMarc software, which includes “extended syntax, faster indexing with multi-threading, easier customization of Java indexing code” (from Summit website above).
VuFind Summit could not be promoted, nor indeed occur, without speaking of Demian Katz. He is the VuFind Project Manager who has worked here at the Falvey Memorial Library since 2009. Demian brings the conference together each year and has even published scholarly articles on the topic of VuFind. Anyone who has spoken to him, or heard him lecture, can easily detect his passion for innovative technologies and how the user engages with them. His talk will focus on the innovations made since last year’s VuFind Summit, and he will participate heavily in mapping out the next year’s innovations.

Demian Katz lectures at VuFind Summit 2015.
I know, on a personal level, that if you aren’t a coder, then this event might not seem pertinent to you. I encourage you, however, to check out the live stream or the YouTube videos that will be posted subsequently. Not many universities can list “developed an internationally renowned search engine” on their curriculum vitae. VuFind is part of what makes Villanova University a top 50 college in the country; VuFind is part of your daily research experience here at Villanova. It’s certainly worthwhile to give attention to those specialists who make VuFind a reality.

Article by William Repetto, a graduate assistant on the Communications and Marketing Team at the Falvey Memorial Library. He is currently pursuing an MA in English at Villanova University.

For those who don’t know, VuFind is an open-source library resource portal designed and developed for libraries right here by Villanova University’s own Falvey Memorial Library. VuFind replaces the traditional online public access catalog, enabling users to search and browse through all of a library’s resources. We are proud to say that components of this system have been implemented in institutions all over the world!
In order to continue conversations about the system, Falvey Memorial Library has been the home base of several VuFind meetings over the years. In fact, on October 12 and 13, the 2015 VuFind Summit brought to Falvey about fifteen software developers from a variety of places, including Germany and Finland, to discuss the use and future course of VuFind. This event continued some conversations begun at an even larger “community meeting” held the previous week in Germany.

A group shot of the 2015 VuFind Summit Conference attendees!
Presentations at the conference covered some unconventional uses of VuFind – for example, as a website to document a painting restoration project, and a set of genealogy databases – as well as providing tips on how best to manage the software, including a fascinating discussion on how to enable the software to run without interruption even when searching huge numbers of records under heavy load.
The planning session and subsequent “hackfest” led to some useful discussions about interoperability and reusability and suggest that future development of the software will focus on allowing VuFind to interact with a wider variety of systems and be reused in novel ways. Welcoming developers from distant places to interact in person also led to some useful knowledge sharing, particularly with regard to new features of VuFind’s underlying tools, and this exchange of knowledge will likely result in performance improvements in the next release of the package.

Demian Katz took notes at the 2015 VuFind Summit.
It is conventional programmer’s wisdom that “software is never done,” and this is certainly true of VuFind – a mature and widely used package that nonetheless always has room for growth and improvement. Regular meetings like the VuFind Summit help to re-energize that growth and keep the project alive and on track.
Contributed by Demian Katz, library technology development specialist
The Problem
VuFind follows a fairly common software design pattern: it discourages users from making changes to core files, and instead encourages them to copy files out of the core and modify them in a local location. This has several advantages, including putting all of your changes in one place (very useful when a newcomer needs to learn how you have customized a project) and easing upgrades (you can update the core files without worrying about which ones you have changed).
There is one significant disadvantage, however: when the core files change, your copies get out of sync. Keeping your local copies synched up with the core files requires a lot of time-consuming, error-prone manual effort.
Or does it?
The Solution
One argument against modifying files in a local directory is that, if you use a version control tool like Git, the advantages of the “local customization directory” approach are diminished, since Git provides a different mechanism for reviewing all local changes to a code base and for handling software updates. If you modify files in place, then “git merge” will help you deal with updates to the core code.
Of course, the Git solution has its own drawbacks — and VuFind would lose some key functionality (the ability for a single instance to manage multiple configurations at different URLs) if we threw away our separation of local settings from core code.
Fortunately, you can have the best of both worlds. It’s just a matter of wrangling Git and a 3-way merge tool properly.
Three Way Merges
To understand the solution to the problem, you need to understand what a three-way merge is. Essentially, this is an algorithm that takes three files: an “old” file, and two “new” files that each have applied different changes to the “old” file. The algorithm attempts to reconcile the changes in both of the “new” files so that they can be combined into a single output. In cases where each “new” file has made a different change in the same place, the algorithm inserts “conflict markers” so that a human can manually reconcile the situation.
Whenever you merge a branch in Git, it is doing a three-way merge. The “old” file is the nearest common ancestor version between your branch and the branch being merged in. The “new” files are the versions of the same file at the tips of the two branches.
If we could just do a custom three-way merge, where the “old” file was the common ancestor between our local version of the file and the core version of the file, with the local/core versions as the “new” files, then we could automate much of the work of updating our local files.
Fortunately, we can.
Lining Up the Pieces
Solving this problem assumes a particular environment (which happens to be the environment we use at Villanova to manage our VuFind instances): a Git repository forked from the main VuFind public repository, with a custom theme and a local settings directory added.
Assume that we have this repository in a state where all of our local files are perfectly synched up with the core files, but that the upstream public repository has changed. Here’s what we need to do:
1.) Merge the upstream master code so that the core files are updated.
2.) For each of our locally customized files, perform a three-way merge. The old file is the core file prior to the merge; the new files are the core file after the merge and the local file.
3.) Manually resolve any conflicts caused by the merging, and commit the local changes.
Obviously step 2 is the hard part… but it’s not actually that hard. If you do the local updates immediately after the merge commit, you can easily retrieve pre-merge versions of files using the “git show HEAD~1:/path/to/file” command. That means you have ready access to all three pieces you need for three-way merging, and the rest is just a matter of automation.
The Script
The following Bash script is the one we use for updating our local instance of VuFind. The key piece is the merge_directory function definition, which accepts a local directory and the core equivalent as parameters. We use this to sync up various configuration files, Javascript code and templates. Note that for configurations, we merge local directories with core directories; for themes, we merge custom themes with their parents.
The actual logic is surprisingly simple. We use recursion to navigate through the local directory and look at all of the local files. For each file, we use string manipulation to figure out what the core version should be called. If the core version exists, we use the previously-mentioned Git magic to pull the old version into the /tmp directory. Then we use the diff3 three-way merge tool to do the heavy lifting, overwriting the local file with the new merged version. We echo out a few helpful messages along the way so users are aware of conflicts and skipped files.
#!/bin/bash
function merge_directory
{
echo merge_directory $1 $2
local localDir=$1
local localDirLength=${#localDir}
local coreDir=$2
for current in $localDir/*
do
local coreEquivalent=$coreDir${current:$localDirLength}
if [ -d "$current" ]
then
merge_directory "$current" "$coreEquivalent"
else
local oldFile="/tmp/tmp-merge-old-`basename "$coreEquivalent"`"
local newFile="/tmp/tmp-merge-new-`basename "$coreEquivalent"`"
if [ -f "$coreEquivalent" ]
then
git show HEAD~1:$coreEquivalent > $oldFile
diff3 -m "$current" "$oldFile" "$coreEquivalent" > "$newFile"
if [ $? == 1 ]
then
echo "CONFLICT: $current"
fi
cp $newFile $current
else
echo "Skipping $current; no equivalent in core code."
fi
fi
done
}
merge_directory local/harvest harvest
merge_directory local/import import
merge_directory local/config/vufind config/vufind
merge_directory themes/vuboot3/templates themes/bootstrap3/templates
merge_directory themes/villanova_mobile/templates themes/jquerymobile/templates
merge_directory themes/vuboot3/js themes/bootstrap3/js
merge_directory themes/villanova_mobile/js themes/jquerymobile/js
Conclusion
I’ve been frustrated by this problem for years, and yet the solution is surprisingly simple — I’m glad it finally came to me. Please feel free to use this for your own purposes, and let me know if you have any questions or problems!

Infographic designed by Joanne Quinn with copy and invaluable assistance provided by Demian Katz and Darren Poley.
Villanova University’s Digital Library has recently upgraded its discovery interface, introducing a more detailed search experience. This represents the first major upgrade of the application’s existing structure which was introduced a year ago when it was migrated to a Fedora-Commons Repository and debuted a public interface utilizing the Open Source faceted search engine VuFind.
First we will discuss the systems architecture and components. Fedora (Flexible Extensible Digital Object Repository Architecture) provides the core architecture and services necessary for digital preservation, all accessible through a well-defined Application Programming Interface (API). It also provides numerous support services to facilitate harvesting, fixity, and messaging. It also supports the Resource Description Framework (RDF) by including the Mulgara triple store.
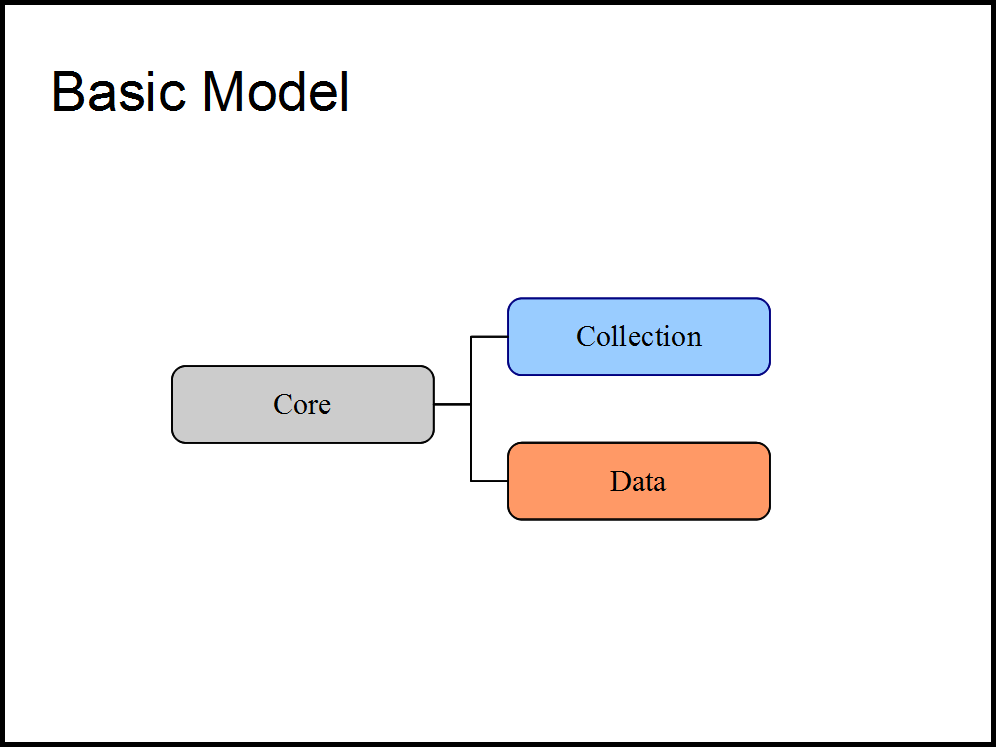
Figure 1
It is through these RDF semantic descriptions that Fedora models the relationships between the objects within the repository. An object’s RDF description contains declarative information regarding what kind of object it is. In our case we created one top-level model (CoreModel) that describes attributes commons among all objects (thumbnails, metadata, licensing information) and two second-level models that represent all basic shapes in the repository (Collections and Data). Collections represent groups of objects and Data objects represent the actual content being stored. (See Figure 1)
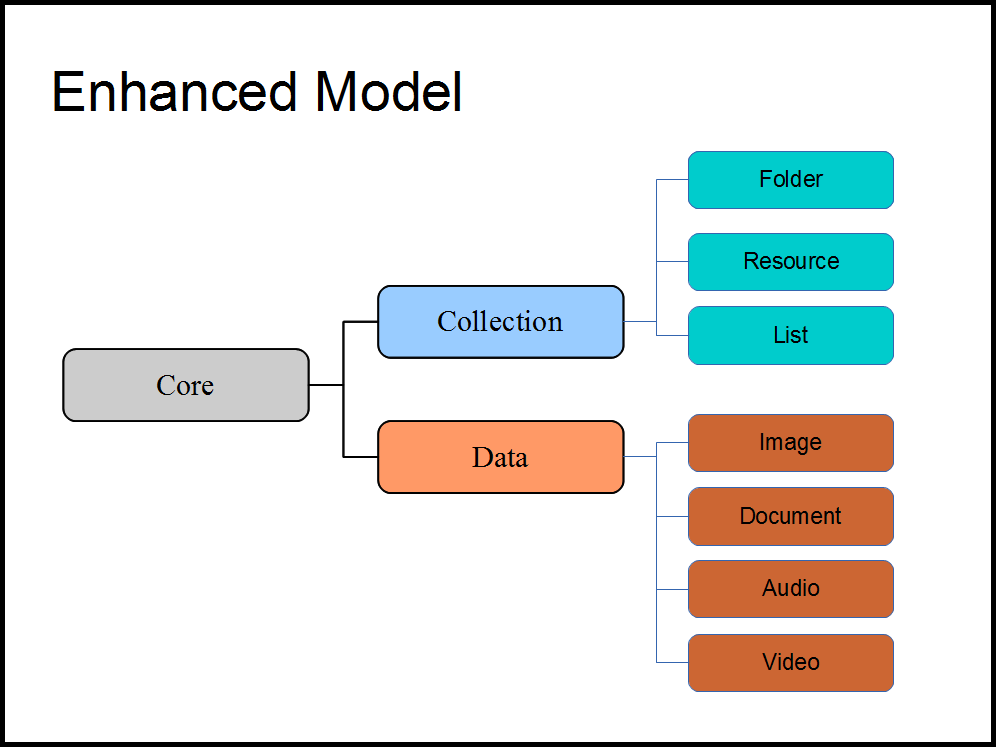
Figure 2
From here we further extrapolated these two models into specific types. Collections can be either Folders or Resources and Data objects can be Images, Audio files, Documents, etc. (See Figure 2)
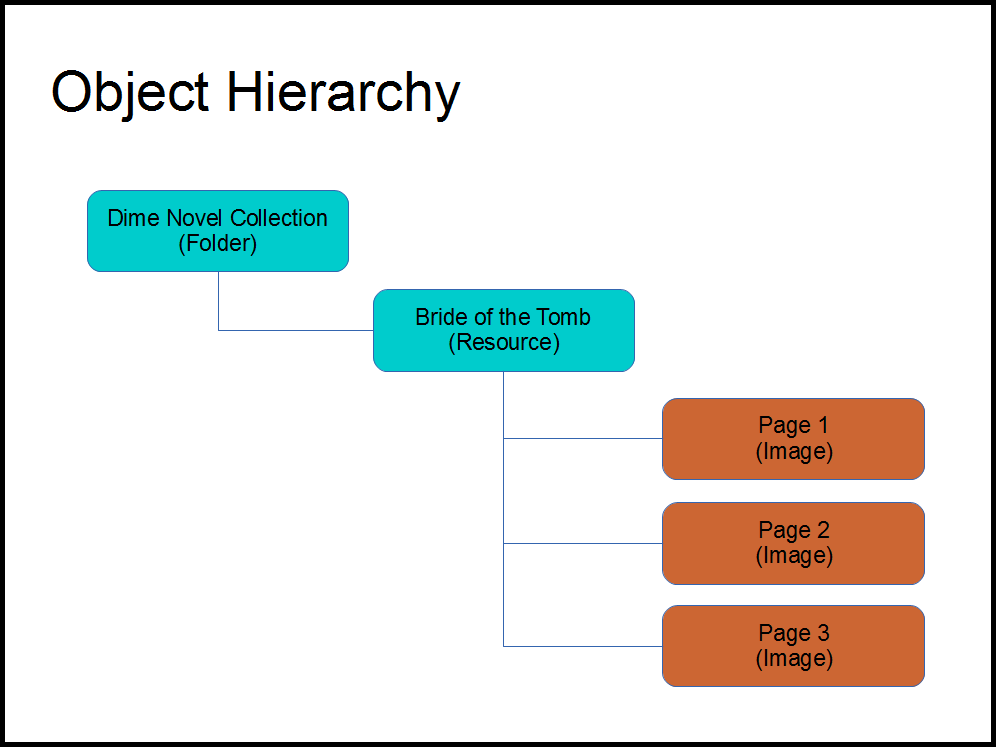
Figure 3
Another important component found within the RDF description is the object’s relationship to other objects. It is this relationship that organizes Resources with their Parent Folder, and book pages within their parent Resource. (See Figure 3)
Look at the following RDF description for our Cuala Press Collection. You can see that it contains two “hasModel” relationships stating that it is both a Collection and Folder (Fedora does not support inheritance in favor of a mixin approach). Note also the one “isMemberOf” relationship referencing vudl:3, the top-level collection of the Digital Library.
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:fedora="info:fedora/fedora-system:def/model#" xmlns:rel="info:fedora/fedora-system:def/relations-external#">
<rdf:Description rdf:about="info:fedora/vudl:2001">
<fedora:hasModel rdf:resource="info:fedora/vudl-system:CollectionModel"/>
<fedora:hasModel rdf:resource="info:fedora/vudl-system:FolderCollection"/>
<rel:isMemberOf rdf:resource="info:fedora/vudl:3"/>
</rdf:Description>
</rdf:RDF>
A more detailed explanation of this data model was presented at Open Repositories 2013. Abstract
Villanova’s Falvey Library is the focal point and lead development partner for VuFind, an Open Source search engine designed specifically around the discovery of bibliographic content. Its recently redesigned core provides a flexible model for searching and displaying our Digital Library, making it the perfect match for the public interface.
The backbone of VuFind is Apache Solr, a Java-based search engine. A simple explanation of how it works is that you put “records” into the Solr search index, each containing predefined fields (title, author, description, etc), and then the application can search through the contents of the index with high speed and efficiency.
Our initial index contained all Resource and Folders from the repository, which allows us to browse through collections by hierarchy, and search receiving both Resources and Folders in the results.

Figure 4
An early enhancement to the browse module made available Collections that reside in multiple locations. For example our Dime Novel collection contains sub-collections whose resources can exist in 2 places. (See Figure 4)
Look at the Buffalo Bill collection and notice how its breadcrumb trail denotes residency in multiple places. This is achieved by adding an additional “is MemberOf” relationship in its RDF description:
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:fedora="info:fedora/fedora-system:def/model#" xmlns:rel="info:fedora/fedora-system:def/relations-external#">
<rdf:Description rdf:about="info:fedora/vudl:279438">
<fedora:hasModel rdf:resource="info:fedora/vudl-system:CollectionModel"/>
<fedora:hasModel rdf:resource="info:fedora/vudl-system:FolderCollection"/>
<rel:isMemberOf rdf:resource="info:fedora/vudl:280419"/>
<rel:isMemberOf rdf:resource="info:fedora/vudl:280425"/>
</rdf:Description>
</rdf:RDF>
The existing search interface supports “full text” searching. We routinely perform Optical Character Recognition (OCR) using Google’s Tesseract application, on all scanned Resources, storing this derivative in the accompanying Data object. When the parent Resource is ingested into Solr, a loop is performed over all of the associated child Data objects, grabbing their OCR file and stuffing it into the full text field for the Resource. This works, as it will match searches from that particular page of the book and direct the patron to the parent Resource, but from there it is often difficult to determine what page matched the query.

Figure 5
A solution to this dilemma was achieved by including all Data objects in the Solr index. This would allow specific pages to be searched in the catalog, leading users to the individual pages that match the query. The first obvious problem with this idea is that the search results would then be cluttered with individual pages, and not the more useful Folders and Resources. This was ultimately overcome by taking advantage of a newer feature in Solr called Field Collapsing. This allows the result set to be grouped by a particular field in Solr. (See Figure 5) In our case we group on the parent Resource, which allows us to display the Resource in the result set and the page which was matched. (See Figure 6) A live example of this can be seen here.

Figure 6
We are pleased to make this available to the world, with the hopes that it will be helpful.
Happy searching…
The components of our infrastructure are all Open Source, freely available applications.
Fedora-Commons Repository
The backbone of the system
VuFind
The public Discovery interface
VuDL
The admin used to ingest objects into Fedora
File Information Tool Set (FITS)
A file metadata extraction tool
Tesseract
A OCR engine
If you follow Villanova’s Digital Library on Twitter, you may have seen this tweet recently:
Check out our new responsive design (thanks to @crhallberg!): http://t.co/VmWL30gonx Play around & let us know what you think! #webdesign
— VillanovaDigitalLib (@VillanovaDigLib) December 5, 2013
Proud to say that the shout-out refers to me, Chris Hallberg, and I’m going into my third year of working on the front end of the Digital Library. That probably doesn’t mean much to you though, so let’s cut to the chase.
aka. what is Chris’ job?
That’s a fancy way of saying that the design of the website adapts to any size screen that it’s viewed on. This is an evolution from the design model of having two completely different websites to handle desktop users (ie. Wolfram Alpha) and mobile users (Wolfram Alpha again, mobile edition). There’s two major problems here: developers have to design, build, test, deploy, host, and update two separate sites; and some functionality is lost.
Faster browsers, faster Internet speeds, and updated web technologies allow web builders to create more powerful web pages than ever before. Web users know this, and they don’t want to settle. They demand the complicated features of the “full” website on their phones and more and more users and mobile browsers try to use their ever increasing phone sizes to look at the desktop version. If you’ve ever tried this, you’ll know a lot of full websites look terrible on phones. This is where responsive design saves the day.
The biggest problem with smaller screens causes features normally laid horizontally, like this text and the navigation on the left, to clobber each other when the real estate vanishes or to become so tiny the crushed text within looks like something out of House of Leaves. Worst, in my opinion, is the horizontal scroll bar that turns your browser into a periscope in a vast, hidden field of content.
Normal

One word per line necessary to fit in these tiny columns

Clobber-ation

Bum bum bum
Responsive design actively reorganizes the page so that this doesn’t happen.
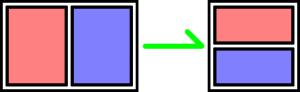
That’s better
Here’s how to properly play with this blog to enjoy responsive design.
If this window is full screen, click the resize button (next to the close button) on this window so that you can see all the edges of the window. Now, drag the right edge of the window to the left, squeeze the window if you will. Come on. It’s ok, no one’s watching. If you don’t do it, the rest of this blog won’t make any sense. Thank you.
The first thing that will happen is that the navigation buttons above (called “pills”) will jump below the search bar. Then, the menus on the very top and below the search bar will collapse into buttons.
Pause a moment. You are entering the land of the Mobily-Sized Browser Window. We designed the new library and digital library web sites to reorganize itself when you look at it on any screen the size of an iPad or smaller. In this case, the menu on the left (and up) is going to move on top of this blog post and fill the available space. We spare no expense! Just keep an eye on the search bar as you squeeze the window down as far as you’d like.
That’s responsive design at work.
In order to make websites look beautiful, developers use a language of rules called CSS, short for Cascading Style Sheets. It looks like this:
button { ← What are we applying the “rules” below to?
background: #002663; ← Villanova blue in code
color: white; ← Color of the text
border: 1px solid black;
border-radius: 4px; ← Rounded corners!
height: 45px;
width: 90px;
margin: 3px ← Distance from border to the next element
padding: 14px 4px; ← Distance from border to content
} ← That’s enough rules for our buttons
That code is more or less how we made the four pills next to the search bar look so pretty.
A year and a half ago, the powers that be added a new feature to CSS: media queries. Media queries can tell us all kinds of things about how you’re looking at our web pages. We can tell whether or not you’re running your browser on a screen, mobile device, TV, projector, screen reader, and even braille reader. It can also tell if you’re holding your phone sideways or vertically, what colors it can display, and (most importantly) what the dimensions of your screen are. By putting code like our button example inside these queries, we can apply rules, like fonts, colors, backgrounds, and borders, to elements of the page depending on the context of the browser.
@media print { ← If we’re printing something
// Hide ads and colorful content
}
@media (max-width: 768px) { ← Anything thinner than a vertical iPad
// Show a special menu for mobile users
}
Responsive designs are built right on top of this technology.
Browsers are really good at stacking things on top of each other. This paragraph is under the previous one. This makes sense and it’s quite easy on your eyes, and your computer. With a few CSS rules, we can tell the browser to put things next to each other. The trick is to put things next to each other, until it’s impractical to do so. Being able to tell your web site where to put things and how they look depending on how and where your user is looking at it is what responsive design is all about.
Before media queries were invented, developers had to write some pretty serious code. This code had to constantly watch the size of the screen and then, basically, rewrite the files where the CSS rules are kept. It was very complicated, which is why it made much more sense to create two completely different sites and route users to each depending on their “user agent,” a small snippet of information that your browser sends to a server when you open a page in your web browser. The problem is, these bits of information were made for people to read for statistical reasons, so they are complicated and change every time a browser updated to a new version. It was a digital guessing game.
Some of the people behind Twitter decided to make a framework that web developers could build on. Instead of starting from scratch, developers could start with their collection of code and CSS that pre-made a lot of common elements of web sites like tabs, accordions, and toolbars, for them. They called it Bootstrap. In 2011, they added responsive design, making it easy for developers to create a site that looked good on any device. In 2012, a graduate assistant named Chris Hallberg was charged with rebuilding the Digital Library front end. In 2013, he, along with web developers all over campus, made Villanova’s web presence responsive. Without this framework, creating a responsive site would have taken much, much longer, and possibly wouldn’t have occurred at all. Not only was it an essential tool to the process, it is a broadcasting platform for the technology. Bootstrap makes responsive design possible and popular.
While I did the work you see over at the Digital Library, I did not create the page you are looking at. I can only take credit for the menu on the left, which I’m clearly very fond of. David Uspal was the magician who conjured this page’s design and David Lacy is the magician behind-the-scenes, organizing and delivering the thousands of books containing the tens of thousands of images we’ve scanned. We both received invaluable input from the Falvey Web Team and even viewers like you. Your feedback helped and continues to help us fix errors and typos, and (most importantly) pick the colors for our pretty new web site.
Enjoy!
– Chris Hallberg
PS. A fun example of the new power of the web is Google Gravity from the gallery of Chrome Experiments.
PPS. As a reward to offset the new habit you’ve developed of resizing every window you find, here’s an accordion to play.