Digital Library upgrade provides enhanced discovery
Villanova University’s Digital Library has recently upgraded its discovery interface, introducing a more detailed search experience. This represents the first major upgrade of the application’s existing structure which was introduced a year ago when it was migrated to a Fedora-Commons Repository and debuted a public interface utilizing the Open Source faceted search engine VuFind.
Part 1 – Modeling the Repository
First we will discuss the systems architecture and components. Fedora (Flexible Extensible Digital Object Repository Architecture) provides the core architecture and services necessary for digital preservation, all accessible through a well-defined Application Programming Interface (API). It also provides numerous support services to facilitate harvesting, fixity, and messaging. It also supports the Resource Description Framework (RDF) by including the Mulgara triple store.
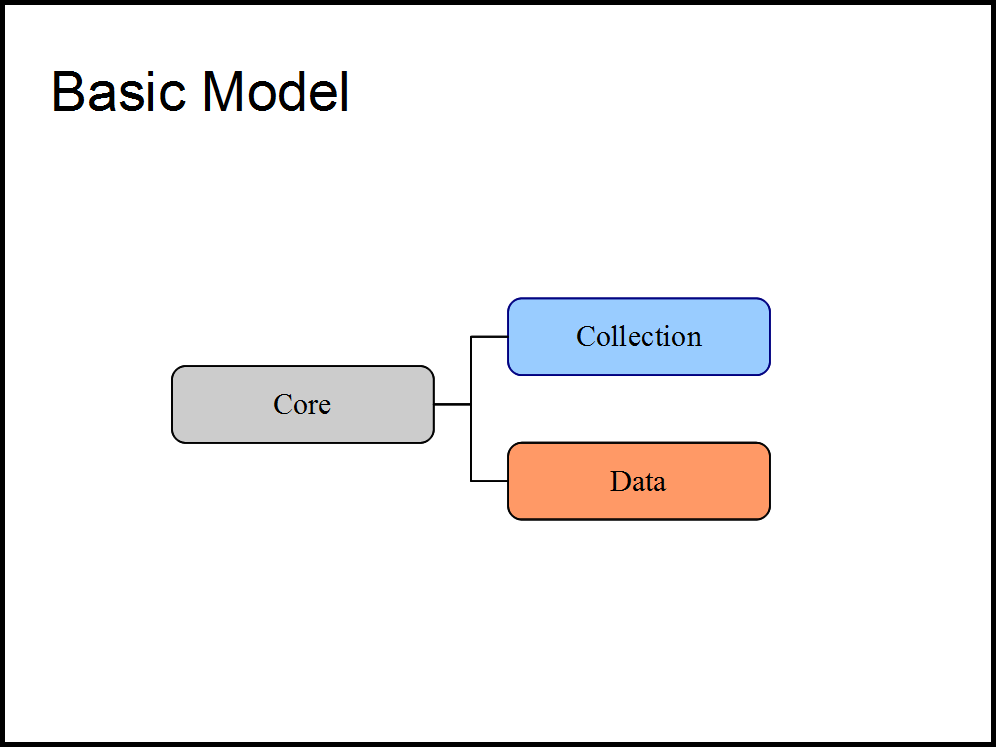
Figure 1
It is through these RDF semantic descriptions that Fedora models the relationships between the objects within the repository. An object’s RDF description contains declarative information regarding what kind of object it is. In our case we created one top-level model (CoreModel) that describes attributes commons among all objects (thumbnails, metadata, licensing information) and two second-level models that represent all basic shapes in the repository (Collections and Data). Collections represent groups of objects and Data objects represent the actual content being stored. (See Figure 1)
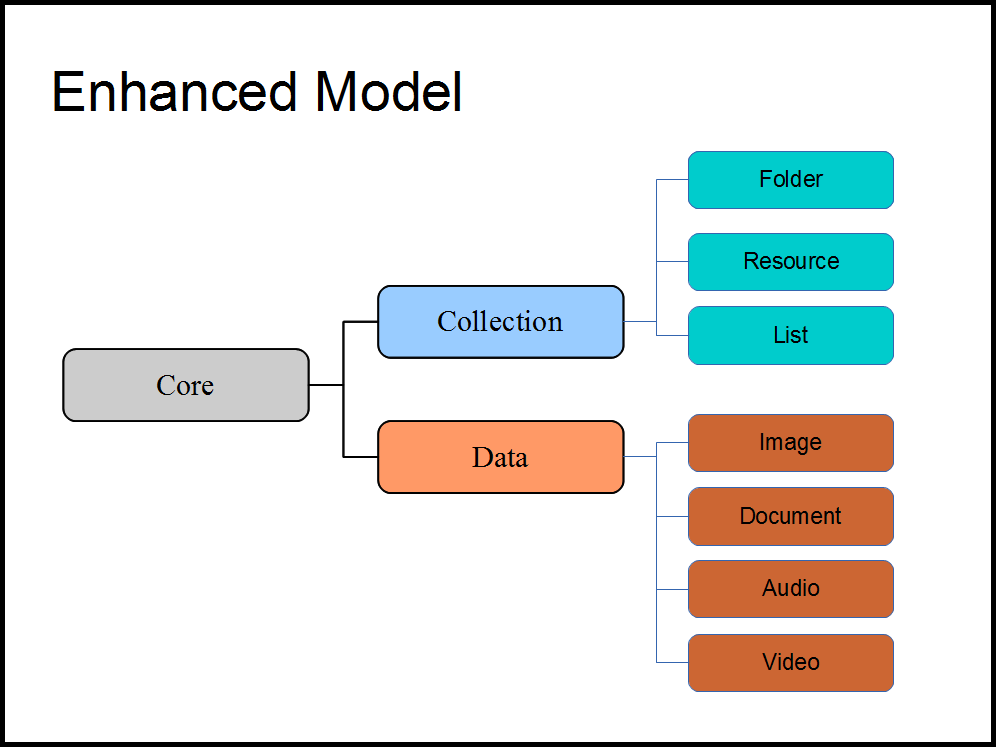
Figure 2
From here we further extrapolated these two models into specific types. Collections can be either Folders or Resources and Data objects can be Images, Audio files, Documents, etc. (See Figure 2)
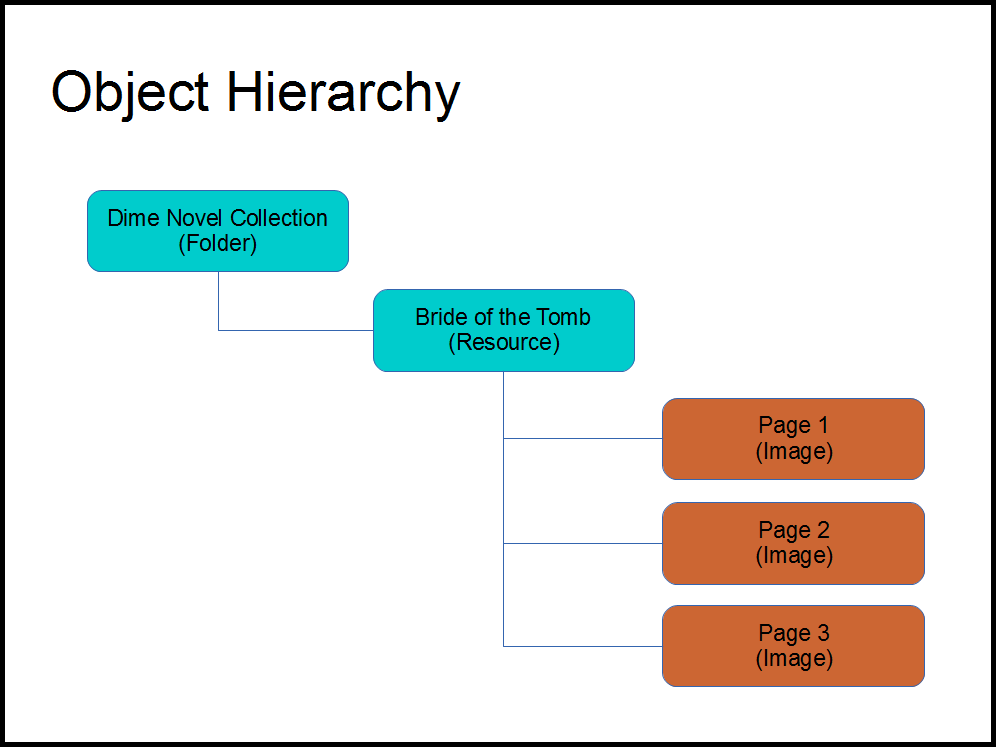
Figure 3
Another important component found within the RDF description is the object’s relationship to other objects. It is this relationship that organizes Resources with their Parent Folder, and book pages within their parent Resource. (See Figure 3)
Look at the following RDF description for our Cuala Press Collection. You can see that it contains two “hasModel” relationships stating that it is both a Collection and Folder (Fedora does not support inheritance in favor of a mixin approach). Note also the one “isMemberOf” relationship referencing vudl:3, the top-level collection of the Digital Library.
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:fedora="info:fedora/fedora-system:def/model#" xmlns:rel="info:fedora/fedora-system:def/relations-external#">
<rdf:Description rdf:about="info:fedora/vudl:2001">
<fedora:hasModel rdf:resource="info:fedora/vudl-system:CollectionModel"/>
<fedora:hasModel rdf:resource="info:fedora/vudl-system:FolderCollection"/>
<rel:isMemberOf rdf:resource="info:fedora/vudl:3"/>
</rdf:Description>
</rdf:RDF>
A more detailed explanation of this data model was presented at Open Repositories 2013. Abstract
Part 2 – The Discovery Layer
Villanova’s Falvey Library is the focal point and lead development partner for VuFind, an Open Source search engine designed specifically around the discovery of bibliographic content. Its recently redesigned core provides a flexible model for searching and displaying our Digital Library, making it the perfect match for the public interface.
The backbone of VuFind is Apache Solr, a Java-based search engine. A simple explanation of how it works is that you put “records” into the Solr search index, each containing predefined fields (title, author, description, etc), and then the application can search through the contents of the index with high speed and efficiency.
Our initial index contained all Resource and Folders from the repository, which allows us to browse through collections by hierarchy, and search receiving both Resources and Folders in the results.

Figure 4
An early enhancement to the browse module made available Collections that reside in multiple locations. For example our Dime Novel collection contains sub-collections whose resources can exist in 2 places. (See Figure 4)
Look at the Buffalo Bill collection and notice how its breadcrumb trail denotes residency in multiple places. This is achieved by adding an additional “is MemberOf” relationship in its RDF description:
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:fedora="info:fedora/fedora-system:def/model#" xmlns:rel="info:fedora/fedora-system:def/relations-external#">
<rdf:Description rdf:about="info:fedora/vudl:279438">
<fedora:hasModel rdf:resource="info:fedora/vudl-system:CollectionModel"/>
<fedora:hasModel rdf:resource="info:fedora/vudl-system:FolderCollection"/>
<rel:isMemberOf rdf:resource="info:fedora/vudl:280419"/>
<rel:isMemberOf rdf:resource="info:fedora/vudl:280425"/>
</rdf:Description>
</rdf:RDF>
Part 3 – The Upgrade
The existing search interface supports “full text” searching. We routinely perform Optical Character Recognition (OCR) using Google’s Tesseract application, on all scanned Resources, storing this derivative in the accompanying Data object. When the parent Resource is ingested into Solr, a loop is performed over all of the associated child Data objects, grabbing their OCR file and stuffing it into the full text field for the Resource. This works, as it will match searches from that particular page of the book and direct the patron to the parent Resource, but from there it is often difficult to determine what page matched the query.

Figure 5
A solution to this dilemma was achieved by including all Data objects in the Solr index. This would allow specific pages to be searched in the catalog, leading users to the individual pages that match the query. The first obvious problem with this idea is that the search results would then be cluttered with individual pages, and not the more useful Folders and Resources. This was ultimately overcome by taking advantage of a newer feature in Solr called Field Collapsing. This allows the result set to be grouped by a particular field in Solr. (See Figure 5) In our case we group on the parent Resource, which allows us to display the Resource in the result set and the page which was matched. (See Figure 6) A live example of this can be seen here.

Figure 6
We are pleased to make this available to the world, with the hopes that it will be helpful.
Happy searching…
Useful Links
The components of our infrastructure are all Open Source, freely available applications.
Fedora-Commons Repository
The backbone of the system
VuFind
The public Discovery interface
VuDL
The admin used to ingest objects into Fedora
File Information Tool Set (FITS)
A file metadata extraction tool
Tesseract
A OCR engine